1. Speaker Voice Characteristics: The speaker is a male, likely in his mid-twenties, with a voice that is slightly strained and carries a hint of weariness, possibly due to stress or fatigue.
2. Primary Emotional State: The primary emotion conveyed by the speaker is a sense of frustration and irritation, which is palpable through their labored breathing and tense vocal delivery.
3. Emotional Layers and Nuance: Underlying this primary emotion, there is also a noticeable undertone of sadness and disappointment. This is evident from the speaker's slow pace and low pitch, which suggest a more profound emotional state than mere annoyance.
4. Emotional Progression: Throughout the audio, the speaker's frustration appears to escalate, culminating in a moment of heightened emotion where their voice cracks, indicating a breaking point in their emotional state.
5. Supporting Vocal Indicators: Vocal indicators such as the roughness and strain in the speaker's voice, coupled with their labored breathing and fluctuating pitch, support the analysis of a complex emotional landscape.
6. Acoustic Environment: The acoustic environment seems to contribute to the overall emotional tone, with a reverberant quality suggesting a large, open space, possibly indicative of a public or formal setting. The lack of background noise allows for a clear focus on the speaker's voice and emotional expression.
7. Overall Emotional Description: In summary, the speaker's voice conveys a deep-seated combination of frustration, sadness, and weariness, reflecting a complex emotional landscape that is both intense and nuanced.
Abstract
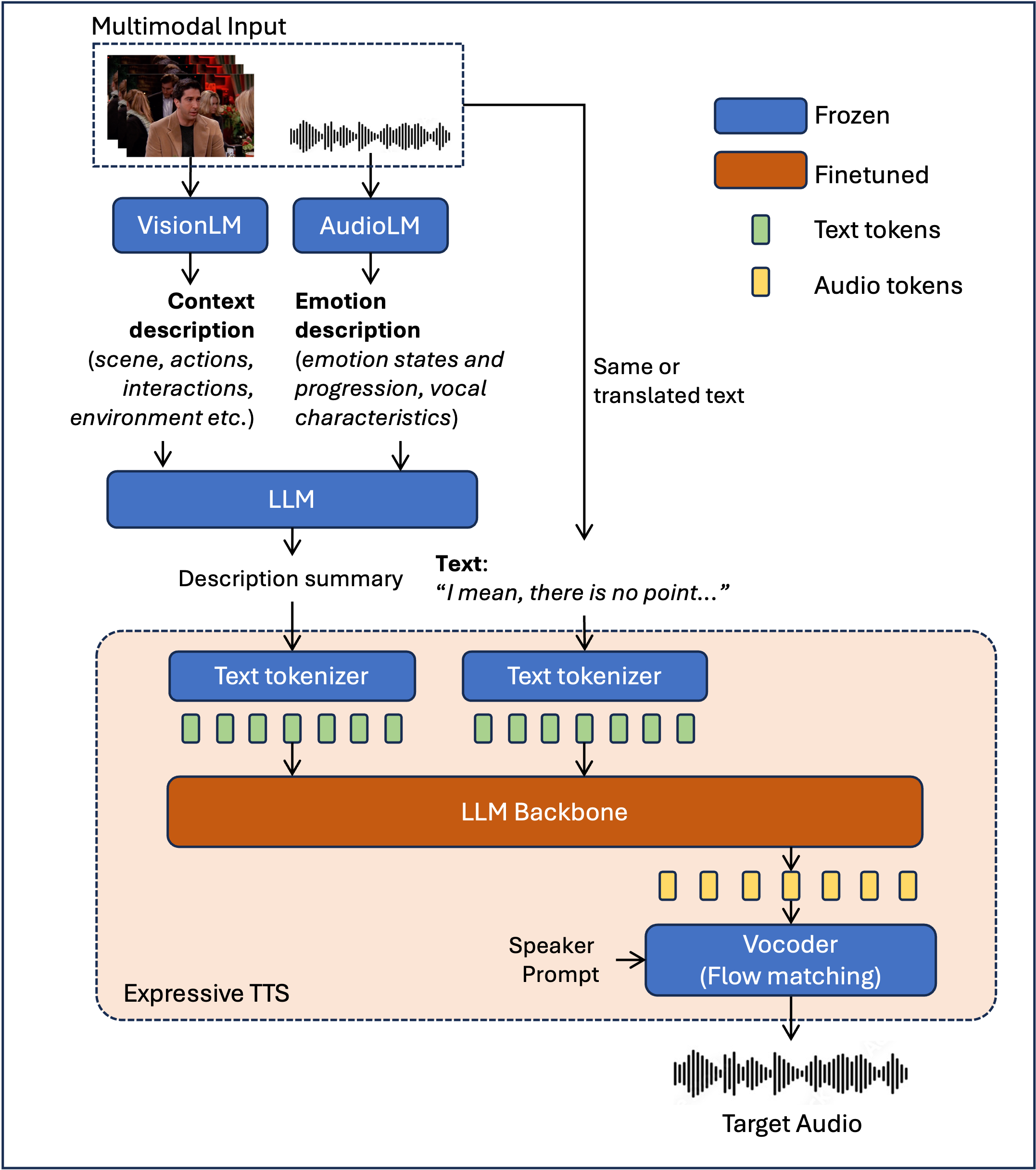
Expressive text-to-speech (TTS) for automated dubbing often misses time-varying emotion and lacks multimodal grounding, which hurts cinematic dubbing quality. We propose PromptDub, the first multimodal controllable dubbing pipeline that integrates vision, audio, and language cues into transparent prompts for expressive TTS. Vision- and audio-language models summarize scene, performance, and delivery; an LLM fuses them into brief, editable directions. We then train a TTS that conditions on these fine-grained prompts and the script to synthesize speech aligned to emotion and timing. We also introduce an emotion-trajectory metric using Dynamic Time Warping (DTW) to assess temporal coherence. Our evaluation showed PromptDub improved global emotion similarity to 0.90 (vs. 0.87), reduces DTW by up to 54%, and is preferred by listeners in ABX tests by 82% for emotion/prosody matching over state-of-the-art baselines.
Block Diagram